¶ Automatisation
Network OVS CNI
https://github.com/ventoy/PXE/releases
https://github.com/goffinet/packer-kvm
https://www.vincentliefooghe.net/content/utilisation-lvm-logical-volume-manager-sous-linux
Installer ProxMox depuis .deb
https://edenmal.moe/post/2016/OpenVSwitch-Multi-Host-Overlay-Network/
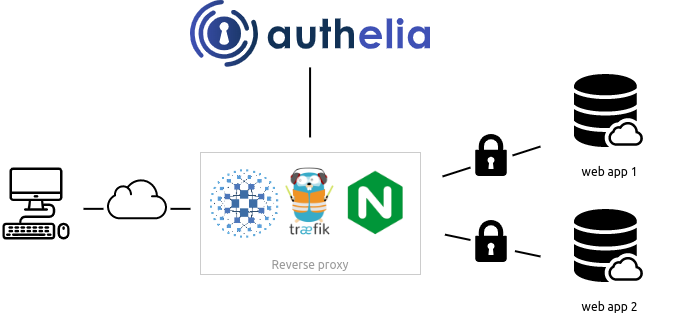
https://www.bujarra.com/monitorizando-raspberry-pi-con-telegraf/
https://www.opsmx.com/blog/argo-cd-installation-into-kubernetes-using-helm-or-manifest/
NAME: argocd
LAST DEPLOYED: Thu Mar 21 18:09:39 2024
NAMESPACE: cluster-infra--argocd
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
In order to access the server UI you have the following options:
1. kubectl port-forward service/argocd-server -n cluster-infra--argocd 8080:443
and then open the browser on http://localhost:8080 and accept the certificate
2. enable ingress in the values file `server.ingress.enabled` and either
- Add the annotation for ssl passthrough: https://argo-cd.readthedocs.io/en/stable/operator-manual/ingress/#option-1-ssl-passthrough
- Set the `configs.params."server.insecure"` in the values file and terminate SSL at your ingress: https://argo-cd.readthedocs.io/en/stable/operator-manual/ingress/#option-2-multiple-ingress-objects-and-hosts
After reaching the UI the first time you can login with username: admin and the random password generated during the installation. You can find the password by running:
kubectl -n cluster-infra--argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d
(You should delete the initial secret afterwards as suggested by the Getting Started Guide: https://argo-cd.readthedocs.io/en/stable/getting_started/#4-login-using-the-cli)
¶ Vdi
¶ Kubernetes
- ArgoCD Astuces
- Messagerie
- Zimbra
- OpenBAO - vault OpenSource
- DKron gestion cron
- Diagram as Code
- Test Selenium
- Images - libreOffice
- SIEM/XDR Wazuh
- Synchro temps réél
- Affinité
- test
- Coder
- LongHorn
- Kubespace
- Teleport - Istaller sur Freebox - Exemple de déploiement
- Minio
- Awx - Upgrade
- Kwatch
- Traefik supervision - Article original
- Grafana
- GlusterFS
- PowerDNS
- Snipset vsCode
- Terraform libVirt
- Terraform libVirt auto
Autoriser accès au matériel
containers:
- name: foo
volumeMounts:
- mountPath: /dev/video0
name: dev-video0
securityContext:
privileged: true
volumes:
- name: dev-video0
hostPath:
path: /dev/video0
¶ Glpi
¶ Pourquoi Kubernetes ?
Bien que les applications modernes vivent à « l’ère des conteneurs », elles ont parcouru un long chemin à travers le déploiement et la virtualisation traditionnels.
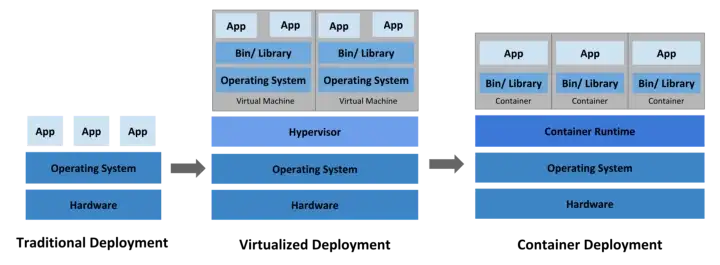
Bien que les conteneurs constituent une excellente approche pour regrouper et exploiter votre application, ils présentent néanmoins des défis qui leur sont propres.
Les conteneurs sont similaires aux machines virtuelles, avec des environnements isolés et une meilleure utilisation des ressources. Comme ils sont découplés de l’infrastructure sous-jacente, ils sont portables à travers le cloud et les distributions d’OS et peuvent être un excellent choix pour exécuter votre application dans des environnements de production.
Cependant, la difficulté ici est que vous devez gérer manuellement les conteneurs en créant des scripts et en vous assurant qu’il n’y a pas de temps d’arrêt. Par exemple, vous devez lancer un autre conteneur si l’un d’eux tombe en panne.
Les défis ne s’arrêtent pas là ,
- Comment les mises à niveau peuvent-elles être effectuées sans temps d’arrêt ?
- Comment ces conteneurs savent-ils comment se parler entre eux ?
- Comment le développeur d’applications peut-il déboguer les problèmes et observer ce qui se passe ?
Cela ne serait-il pas plus facile si un système gérait ce comportement ?
¶ Outils d’orchestration
Tout ce dont les applications modernes ont besoin, sans l’effort manuel de le faire soi-même. Vous avez donc besoin d’un outil capable d’orchestrer efficacement les processus et de garantir que toutes les tâches se déroulent de manière automatisée.

Quelles sont les fonctionnalités offertes par les outils d’orchestration ?
- Fournit une interface unique pour la configuration et la gestion de l’infrastructure.
- Haute disponibilité ou absence de temps d’arrêt.
- Évolutivité ou hautes performances.
- Contrôle d’accès pour les utilisateurs et les services.
- Reprise après sinistre. Sauvegarde et restauration.
¶ Qu’est-ce que Kubernetes ?
Kubernetes est un outil d’orchestration vous permettant d’exécuter et de gérer vos charges de travail basées sur des conteneurs. Kubernetes consiste à gérer ces conteneurs sur des machines virtuelles ou des nœuds. Les nœuds des conteneurs qu’ils exécutent sont regroupés sous forme de cluster et chaque conteneur dispose de points d’extrémité, de DNS, de stockage et d’évolutivité.

Kubernetes a pour but d’héberger votre application sous forme de conteneurs de manière automatisée afin que vous puissiez déployer rapidement autant d’instances de votre application que nécessaire et permettre facilement la communication entre les services au sein de votre application.
Le développeur d’applications indique à Kubernetes à quoi doit ressembler le cluster et Kubernetes s’en charge. Vous pouvez déployer nos applications dans différents environnements tels que les environnements physiques, virtuels, en nuage ou même hybrides.
¶ Quels problèmes Kubernetes résout-il ?
- Équilibrage de charge et découverte de services.
- Mise à l’échelle et autoréparation.
- Techniques automatisées de rollback et de rollout.
- Maximiser l’observabilité.
- L’orchestration du stockage.
- La gestion de la configuration et des secrets.
Il y a donc beaucoup de choses impliquées qui fonctionnent ensemble pour rendre cela possible. voyons celles-ci dans l’architecture kubernetes.
¶ Architecture Kubernetes
Kubernetes fonctionne sur une architecture maître-esclave. Le cluster Kubernetes est constitué d’un ensemble de nœuds qui peuvent être physiques ou virtuels, sur site ou sur le cloud qui hébergent des applications sous forme de conteneurs.
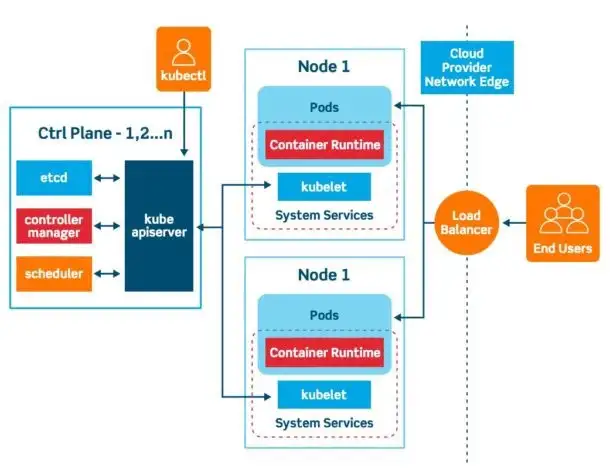
¶ Nœuds maître ou plan de contrôle
Le nœud maître est responsable de la gestion du cluster, du stockage des informations sur les nœuds, de l’ordonnancement et de la surveillance des conteneurs.
Pour ce faire, le nœud maître utilise un ensemble de composants connus sous le nom de composants du plan de contrôle. Explorons chacun de ces composants un par un.
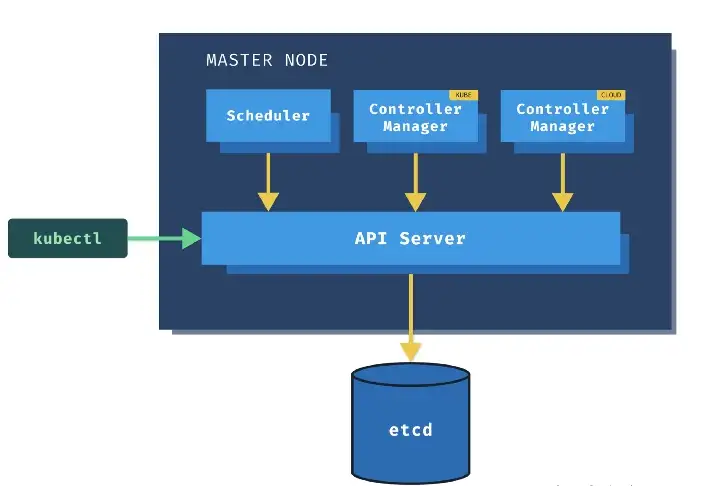
¶ kube-apiserver
Il s’agit du principal composant de gestion chargé d’orchestrer toutes les opérations au sein du cluster Kubernetes. Pensez-y en termes de passerelle de cluster.
Kube-apiserver joue également le rôle de gatekeeper pour l’authentification. Il expose l’API kubernetes que les utilisateurs externes utilisent pour effectuer des opérations de gestion sur le cluster et les différents contrôleurs. L’API est accessible via l’interface de ligne de commande kubectl ou d’autres outils comme kubeadm, et via des appels REST.
¶ kube-controller-manager
Les contrôleurs sont le cerveau de Kubernetes. Ils agissent comme une unité centrale de décision qui contient tous les mécanismes de contrôle. Le gestionnaire de contrôleur surveille l’ensemble de réplication, le nœud, les points de terminaison (services) et les comptes de service.
Il communique avec le kube-apiserver pour lire et écrire tous les statuts. En plus de tout cela, il effectue des tâches telles que la collecte d’événements, la création d’espaces de noms, la collecte de pods terminés, la collecte de suppressions en cascade, la collecte de nœuds, etc.
Le contrôleur de nœuds s’occupe des nœuds ; il est responsable de l’intégration des nouveaux nœuds dans le cluster et gère les situations où les nœuds deviennent indisponibles ou sont détruits.
En outre, le contrôleur de réplication s’assure que le nombre souhaité de conteneurs est en cours d’exécution.
¶ etcd
De nombreux conteneurs sont créés et supprimés à la demande, il doit donc y avoir un mécanisme qui doit maintenir des informations sur les différents conteneurs telles que
- Sur quel nœud le conteneur s’exécute-t-il ?
- À quelle heure il est créé ?
ETCD est une base de données pour le cluster kubernetes qui stocke de telles informations au format clé-valeur. Il stocke les configurations du cluster Kubernetes, les secrets et les représente dans la base de données clé-valeur.
¶ kube-scheduler
L’ordonnanceur est chargé de prendre les décisions d’ordonnancement. Il identifie les conteneurs qui doivent être placés sur les nœuds.
Il identifie le bon nœud en fonction des besoins en ressources, de sa capacité et d’autres politiques et contraintes telles que les taints et les tolérances ou les règles d’affinité des nœuds qui leur sont appliquées.
¶ gestionnaire de contrôleur de nuage
Ce composant a la capacité d’intégrer une logique de contrôle spécifique au cloud ; par exemple, il peut utiliser le service d’équilibreur de charge proposé par le fournisseur de cloud. Vous pouvez l’utiliser pour relier un cluster Kubernetes avec l’API d’un fournisseur de cloud.
En outre, il contribue au découplage du cluster Kubernetes des éléments qui communiquent avec les plateformes de cloud computing, de sorte que les composants à l’intérieur du cluster n’ont pas besoin de connaître les détails de mise en œuvre de chaque fournisseur de cloud computing.
¶ Nœuds de travail
Nous allons maintenant nous concentrer sur le nœud de travail. Un composant ou un agent doit être chargé de gérer toutes les activités sur ces nœuds.
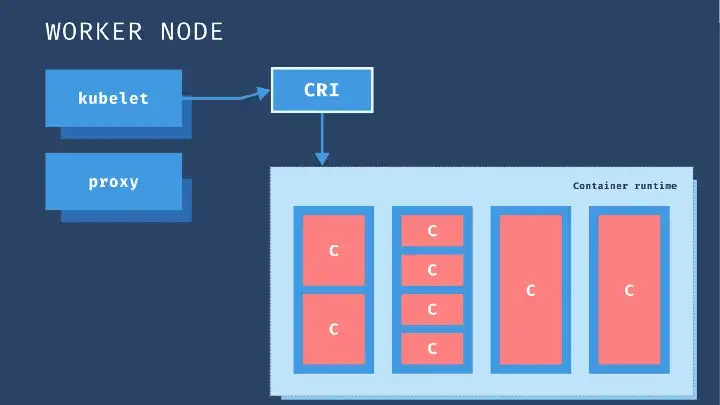
¶ interface d’exécution de conteneur
Les conteneurs sont au cœur de notre processus et nous avons donc besoin que tout soit compatible avec les conteneurs. Notre application se présente sous la forme d’un conteneur et les différents composants qui constituent l’ensemble du système de gestion sur le nœud maître pourraient être hébergés également sous la forme de conteneurs.
De plus, les services DNS et les solutions de mise en réseau peuvent tous être déployés sous forme de conteneurs. Nous avons donc besoin d’un logiciel capable d’exécuter les conteneurs, à savoir le moteur d’exécution de conteneurs.
Un moteur populaire est Docker. Ainsi, Docker ou tout autre moteur d’exécution de conteneur équivalent, tel que containerd, doit être installé sur tous les nœuds du cluster, y compris les nœuds maîtres.
¶ kubelet
Le kubelet est un agent qui s’exécute sur chaque nœud d’un cluster. Il écoute en permanence les instructions de kube-apiserver et déploie et détruit les conteneurs sur les nœuds si kube-apiserver le demande.
Kube-apiserver récupère périodiquement les rapports d’état de la kubelet pour surveiller l’état des nœuds et des conteneurs qui s’y trouvent. Ainsi, la kubelet interagit à la fois avec le conteneur et le nœud.
La kubelet démarre le pod avec un conteneur à l’intérieur et attribue les ressources aux conteneurs à partir de ce nœud, comme le CPU, la RAM et les ressources de stockage.
Mais l’application qui s’exécute sur les nœuds de travail doit communiquer entre eux. Par exemple, comment le conteneur backend de l’application et le serveur de base de données communiqueraient-ils ?
¶ kube-proxy
La communication entre les nœuds de travail est assurée par un autre composant exécuté sur chaque nœud de travail, le service Kube-proxy.
Il s’assure que les règles nécessaires sont placées pour permettre la communication entre les différents conteneurs fonctionnant sur les nœuds de travail. Le proxy Kube veille à ce que la communication se fasse avec une faible surcharge.
¶ Nombre de pods par noeuds
¶ Optimiser l’allocation d’adresses IP
Cette page explique comment configurer le nombre maximal de pods pouvant être exécutés sur un nœud pour les clusters standards. Cette valeur détermine la taille des plages d’adresses IP attribuées aux nœuds sur Google Kubernetes Engine (GKE). Les pods qui s’exécutent sur un nœud se voient attribuer des adresses IP à partir de la plage d’adressage CIDR du nœud.
Les étapes décrites sur cette page ne s’appliquent pas aux clusters Autopilot, car le nombre maximal de nœuds est préconfiguré et immuable.
Présentation
Par défaut, GKE autorise jusqu’à 110 pods par nœud sur les clusters standards, mais les clusters standards peuvent être configurés pour autoriser jusqu’à 256 pods par nœud. Les clusters Autopilot disposent d’un maximum de 32 pods par nœud. Kubernetes attribue à chaque nœud une plage d’adresses IP, un bloc CIDR, afin que chaque pod puisse avoir une adresse IP unique. La taille du bloc CIDR correspond au nombre maximal de pods par nœud.
Plages CIDR pour les clusters standards
Avec un maximum par défaut de 110 pods par nœud pour les clusters standards, Kubernetes affecte un bloc CIDR /24 (256 adresses) à chacun des nœuds. Avec un nombre d’adresses IP disponibles plus de deux fois supérieur au nombre maximal de pods pouvant être créés sur un nœud, Kubernetes peut réduire la réutilisation des adresses IP lorsque des pods sont ajoutés et supprimés d’un nœud.
Bien que la limite de 256 pods par nœud soit une limite stricte, vous pouvez réduire le nombre de pods sur un nœud. La taille du bloc CIDR attribué à un nœud dépend du nombre maximal de pods par valeur de nœud. Le bloc contient toujours au moins deux fois plus d’adresses que le nombre maximal de pods par nœud.
Le tableau suivant répertorie la taille du bloc CIDR et le nombre correspondant d’adresses IP disponibles que Kubernetes attribue aux nœuds en fonction du nombre maximal de pods par nœud :
Nombre maximal de pods par nœud Plage CIDR par nœud Nombre d’adresses IP
8 /28 16
9 – 16 /27 32
17 – 32 /26 64
33 – 64 /25 128
65-128 /24 256
129 - 256 /23 512
Remarque : La définition du nombre maximal de pods par nœud dépassant la limite par défaut de 110 n’est disponible que pour les versions 1.23.5-gke.1300 et ultérieures de GKE.
Paramètres CIDR pour les clusters Autopilot
Les paramètres par défaut des tailles CIDR des clusters Autopilot sont les suivants :
Plage de sous-réseaux : /23
Plage d'adresses IP secondaire pour les pods : /17
Plage d'adresses IP secondaire pour les services : /22
Autopilot comporte un nombre maximal de pods par nœud de 32. Comme pour GKE Standard, cela signifie qu’une plage /26 est configurée pour chaque nœud, soit 64 adresses IP. Une plage d’adresses de pods de /17 correspond à un cluster pouvant accepter un maximum de 511 nœuds (32 766 adresses IP utilisables / 64 adresses IP par nœud).
Assurez-vous que la plage d’adresses IP secondaire des pods que vous spécifiez est suffisamment grande pour accepter la taille maximale attendue pour les clusters. Une plage de /16 (par exemple, cluster-ipv4-cidr=10.0.0.0/16) est recommandée pour permettre une croissance maximale du cluster.
Réduire le nombre maximal de pods
La réduction du nombre maximal de pods par nœud permet au cluster d’avoir plus de nœuds, car chaque nœud nécessite une plus petite partie de l’espace total alloué aux adresses IP. Vous pouvez également accepter le même nombre de nœuds dans le cluster en spécifiant un espace pour les adresses IP plus petit pour les pods au moment de la création du cluster.
La réduction du nombre maximal de pods par nœud vous permet également de créer des clusters plus petits nécessitant moins d’adresses IP. Par exemple, avec huit pods par nœud, chaque pod reçoit une plage CIDR /28. Ces plages d’adresses IP, ainsi que les plages secondaires et de sous-réseau que vous définissez déterminent le nombre d’adresses IP requis pour créer un cluster.
Vous pouvez configurer le nombre maximal de pods par nœud au moment de la création du cluster et du pool de nœuds.
Restrictions
Vous ne pouvez configurer le nombre maximal de pods par nœud que dans les clusters de VPC natif.
La création de nœuds est limitée par le nombre d’adresses disponibles dans la plage d’adresses allouée aux pods. Consultez le tableau de planification de plages d’adresses IP pour connaître les tailles par défaut, ainsi que les tailles minimales et maximales de la plage d’adresses allouée aux pods. Vous pouvez également ajouter des adresses IP de pods supplémentaires à l’aide d’un CIDR multi-pod non contigu.
Chaque cluster doit créer des pods kube-system, tels que kube-proxy, dans l’espace de noms kube-system. Pensez à prendre en compte vos pods de charge de travail et vos pods système lorsque vous réduisez le nombre maximal de pods par nœud. Pour répertorier les pods système dans votre cluster, exécutez la commande suivante :
kubectl get pods --namespace kube-system
Configurer le nombre maximal de pods par nœud
Vous pouvez configurer le nombre maximal de pods par nœud lors de la création d’un cluster ou d’un pool de nœuds. Vous ne pouvez pas modifier ce paramètre une fois le cluster ou le pool de nœuds créé.
Toutefois, si vous n’avez plus d’adresses IP de pod, vous pouvez créer des plages d’adresses IP de pod supplémentaires à l’aide du CIDR multipod non contigugu.
Vous pouvez définir la taille de la plage d’adresses du pod lors de la création d’un cluster en utilisant gcloud CLI ou Google Cloud Console.
gcloud
Console
Pour définir le nombre maximal de pods par nœud en utilisant gcloud CLI, exécutez la commande suivante :
gcloud container clusters create CLUSTER_NAME
–enable-ip-alias
–cluster-ipv4-cidr 10.0.0.0/21
–services-ipv4-cidr 10.4.0.0/19
–create-subnetwork name='SUBNET_NAME
',range=10.4.32.0/27
–default-max-pods-per-node MAXIMUM_PODS
–zone COMPUTE_ZONE
Remplacez les éléments suivants :
CLUSTER_NAME : nom de votre nouveau cluster
SUBNET_NAME : nom du nouveau sous-réseau pour votre cluster.
MAXIMUM_PODS : nombre maximal de pods par nœud pour le cluster, pouvant être configuré jusqu'à 256. Si cette valeur est omise, Kubernetes attribue la valeur par défaut 110.
COMPUTE_ZONE : zone de calcul de votre cluster.
Lorsque vous configurez le nombre maximal de pods par nœud pour le cluster, Kubernetes utilise cette valeur pour allouer une plage CIDR aux nœuds. Vous pouvez calculer le nombre maximal de nœuds sur le cluster en fonction de la plage d’adresse IP du cluster pour les pods et de la plage CIDR allouée pour le nœud.
Par exemple, si vous définissez le nombre maximal de pods par défaut sur 110 et la plage d’adresses IP secondaire des pods sur /21, Kubernetes attribue une plage CIDR /24 aux nœuds du nœud. Cela autorise un maximum de 2(24-21) = 23 = 8 nœuds sur le cluster.
De même, si vous définissez le nombre maximal de pods par défaut sur 8 et la plage d’adresses IP secondaire du cluster pour les pods sur /21, Kubernetes attribue une plage CIDR /28 aux nœuds. Cela autorise un maximum de 2(28-21) = 27 = 128 nœuds sur le cluster.
Définir le nombre maximal de pods dans un nouveau pool de nœuds pour un cluster existant
Vous pouvez également spécifier le nombre maximal de pods par nœud lors de la création d’un pool de nœuds dans un cluster existant. La création d’un pool de nœuds vous permet d’optimiser l’allocation d’adresses IP, même dans les clusters existants où aucun nombre maximal par défaut de pods par nœud n’est configuré au niveau du cluster.
La définition du nombre maximal de pods au niveau du pool de nœuds remplace la valeur maximale par défaut définie au niveau du cluster. Si vous ne configurez pas de nombre maximal de pods par nœud lorsque vous créez le pool de nœuds, le nombre maximal au niveau du cluster s’applique.
gcloud
Console
gcloud container node-pools create POOL_NAME
–cluster CLUSTER_NAME
–max-pods-per-node MAXIMUM_PODS
Remplacez l’élément suivant :
POOL_NAME : nom de votre nouveau pool de nœuds.
CLUSTER_NAME : nom du cluster dans lequel vous souhaitez créer le pool de nœuds.
MAXIMUM_PODS : nombre maximal de nœuds dans le pool de nœuds.
¶ Sécuriser K8s avec Kubescape
¶ Analyser le réseau avec K8sPacket
¶ Utiliser les side-cars pour débugger
¶ AutoScaler
¶ Installer K8s sur PowerPC
terraform {
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "~> 1.48.0"
}
random = {
}
}
}
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join p10s-k8s02-m01.asten.asten:6443 --token o4am5x.qvd1qpunws7uv969 \
--discovery-token-ca-cert-hash sha256:83000a31dac46c2d3a84442415c55df3dd329d4d3491dba5dd2301b2bd129734 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join p10s-k8s02-m01.asten.asten:6443 --token o4am5x.qvd1qpunws7uv969 \
--discovery-token-ca-cert-hash sha256:83000a31dac46c2d3a84442415c55df3dd329d4d3491dba5dd2301b2bd129734
¶ TroubleShooting
¶ Autoscaling
¶ Les sondes
¶ Les volumes
¶ Kubectl avec plusieurs clusters
Utiliser Kubectl avec plusieurs clusters
¶ Utilisation (Apps)
-
10 Things You Should Know Before Writing a Kubernetes Controller
-
Let’s create your first Kubernetes Operator with operator-sdk
¶ Choisir un node
¶ Sécuriser Kubernetes
¶ Gitops
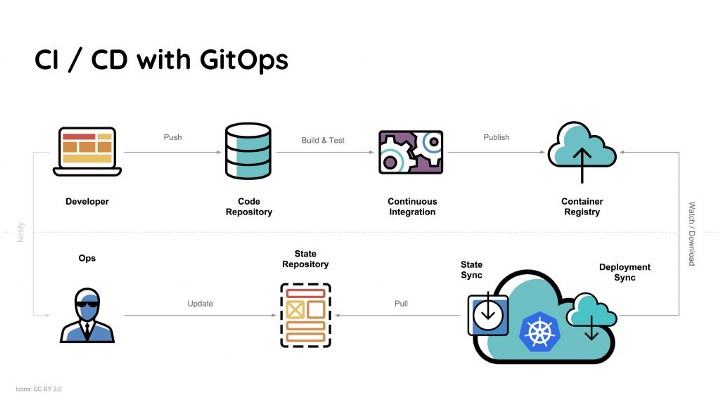
![]()
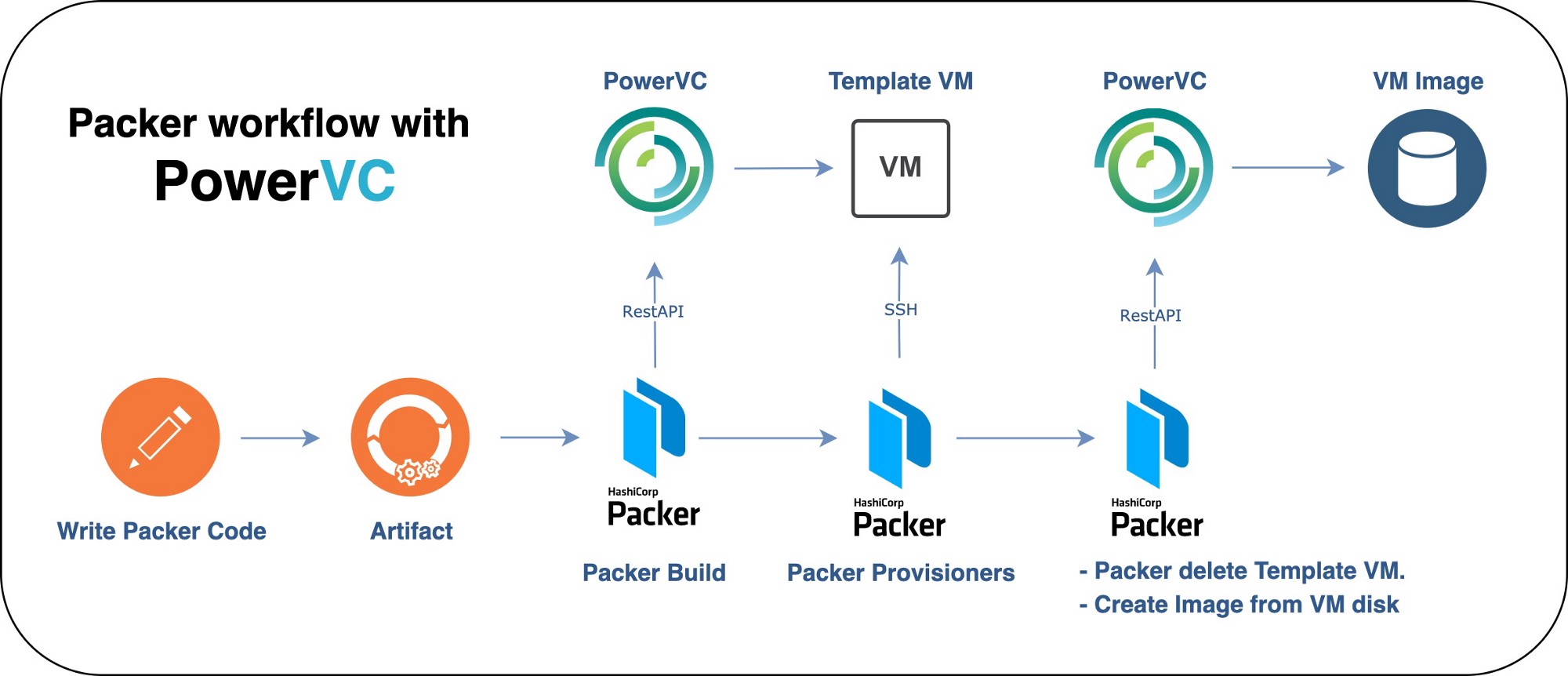
Example :
¶ Sauvegarder une application
Ce document décrit comment sauvegarder une application sur un service S3