¶ Squests
¶ Introduction
Squest est un logiciel libre (APLv2) permettant d’exposer de l’automatisation, basée sur Ansible Tower/AWX, en tant que service (mode SaaS).
Ansible Tower et sa version libre AWX sont une console centrale de gestion des tâches d’automatisation, pour Ansible qui sert à automatiser la gestion et la configuration d’ordinateurs. Ces outils sont notamment utilisés par des profils ingénierie de la fiabilité des sites (SRE Site Reliability Engineering) ou DevOps.
Il existe une vidéo d’introduction à Squest.

Squest propose, pour le moment, deux principales fonctionnalités :
- un catalogue de services
- un gestionnaire de suivi de ressources
¶ Le catalogue de services
¶ Provisioning de ressources
Le cas d’usage de notre équipe est le suivant : nous proposons des services d’infrastructures comme des machines physiques et virtuelles, des clusters dédiés sur Kubernetes, Openstack ou encore Openshift.
Pour la création de ces services nous reposons sur des playbooks Ansible que nous lançons depuis Ansible Tower/AWX.
Nous ne souhaitons pas donner accès directement à Tower à nos utilisateurs finaux pour de multiples raisons mais principalement aussi parce que nous souhaitons approuver les demandes.
Grâce à Squest, nous créons des services dans un catalogue (par exemple « VM dans un vCenter ») que l’utilisateur peut commander.
En qualité d’administrateur nous pouvons vérifier les demandes, les modifier et les valider afin qu’elles soient exécutées par Tower/AWX.
Les services sont donc des pointeurs vers les jobs templates que vous avez créés du coté de Tower/AWX. Cela rend Squest générique et permet d’ajouter autant de services que vous avez d’automatisations disponibles du coté de vos playbooks.
¶ Cycle de vie des instances
Chaque requête approuvée et provisionnée donne naissance à une instance du service sélectionné.
Cette instance permet à l’utilisateur d’effectuer plus tard de nouvelles requêtes, afin de gérer le cycle de vie.
Prenons un exemple concret. Vous avez un service qui permet la creation de machines virtuelles.
La première opération fait appel à un script Ansible qui va provisionner la machine virtuelle (VM) dans l’hyperviseur.
On peut alors imaginer de nouvelles opérations permettant de:
- Changer les caractéristiques de la VM (vCPU, memoire, disque,…)
- Réinstancier le système
- Supprimer la VM
Là où certains outils de ce type sont de type fire and forget et ne permettent que de provisionner des resources, Squest peut associer des opérations de mise à jour ou de suppression sur les instances qu’il a créées afin de pousser au maximum l’autonomie des utilisateurs.
¶ Le suivi des resources
Le suivi de ressources permet à l’administrateur de connaître l’état de consommation de son infrastructure.
Une vidéo démo de cette fonctionnalité est disponible.
![]()
De nos jours, les infrastructures IT sont composées de multiples niveaux : serveurs physiques, machines virtuelles, conteneurs,…
Chaque niveau est alors producteur ou consommateur des ressources d’un autre.
En qualité d’administrateur système, la supervision de la consommation de chaque niveau est nécessaire afin de valider les demandes de service.
La fonctionnalité de suivi de ressources permet de visualiser et de mettre en lumière les ensembles de ressources des infrastructures.
Chaque ressource peut être liée à une instance du catalogue de service qui peut elle-même être liée à un groupe de facturation.
Un tableau de bord permet enfin un visualiser la consommation de chaque groupe.
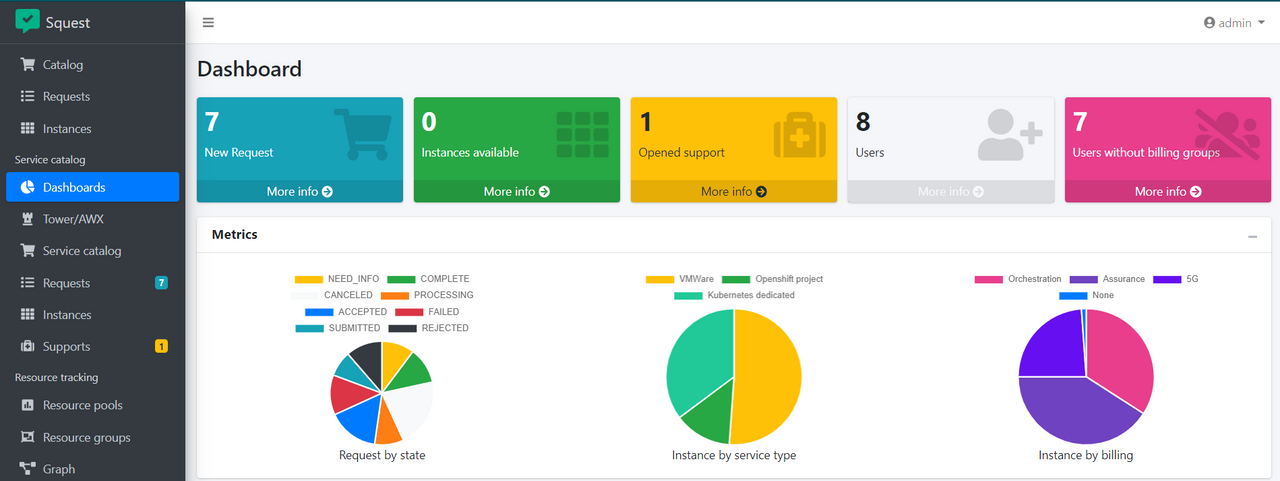
Squest, le portail de service pour Tower/AWX, en version 1.0
Article
¶ Administration système
L’équipe de développement est heureuse de vous annoncer la sortie de la première version prête pour la production de Squest, l’outil à destination des DevOPs/SRE.
Pour rappel, Squest, que vous retrouverez en introduction dans une dépêche précédente dans sa version alpha, est un outil auto hébergé vous permettant d’exposer votre automatisation disponible depuis votre instance de Ansible Tower/AWX en tant que service.
Après un résumé des principales nouveautés, nous allons vous présenter un tutoriel de création d’un service.
¶ Résumé des principales nouveautés
- Image docker officielle ;
- Gestion des annonces aux utilisateurs ;
- Gestion de documentation (markdown) rattachable aux services ;
- Gestion des jetons d’authentification pour l’API ;
- Interface de détails pour les requêtes et les instances ;
- Suppression/archive des requêtes ou instances en tant qu’administrateur ;
- Ajout d’attribut de type « texte » sur les groupes de ressources ;
- Ajout d’un ratio sur les attributs des groupes de ressources ;
- Vérification de la compatibilité avec les « job templates » de Tower/AWX ;
- Gestion intégrée de la sauvegarde.
¶ Tutoriel de création d’un service
Squest permet d’exposer l’automatisation présente dans votre instance d’Ansible Tower/AWX en tant que service.
Nous allons ici exposer un service d’exemple sur le portail Squest. L’objectif est de comprendre les interactions entre le portail et le moteur d’automatisation sous-jacent Ansible.
¶ Provisionner un service
Pour cet exemple, nous souhaitons exposer à nos utilisateurs un service qui permet de créer un fichier sur un serveur Linux et d’y placer du contenu. Voici le code Ansible permettant cette création :
- name: Create a directory with UUID
ansible.builtin.file:
path: "{{ file_path }}"
state: directory
recurse: yes
mode: u+rw,g-wx,o-wx
modification_time: preserve
access_time: preserve
- name: Write the given content in file
ansible.builtin.copy:
content: "{{ file_content }}"
dest: "{{ file_path }}/{{ file_name }}"
Il suffirait donc de placer ce playbook dans un répertoire Git, de déclarer le répertoire sur Tower, et enfin de créer un job template qui pointe sur le playbook.
Seulement voilà, si l’on souhaite effectuer plus tard d’autres opérations sur ce fichier en particulier, par exemple changer le contenu, il faut donner des informations à Squest pour le retrouver. C’est là qu’intervient l’instance.
Lorsqu’un utilisateur effectue une requête pour un service, Squest va automatiquement créer une « instance » et la placer en statut « en attente » (PENDING). L’idée est de faire en sorte que le playbook exécuté appel l’API de Squest afin de donner des informations permettant de retrouver l’objet que nous avons créé (ici un simple fichier).
En résumé la séquence est la suivante :
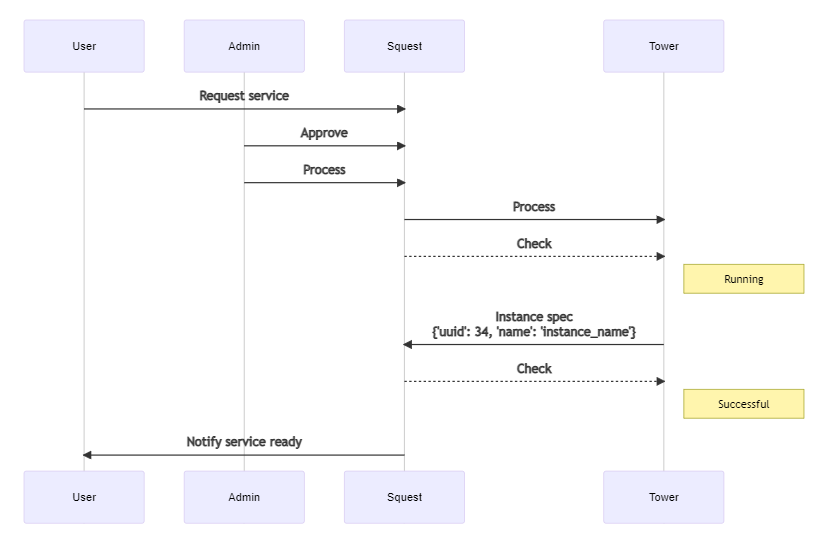
Lorsque le playbook est exécuté sur Tower par la demande de Squest, ce dernier reçoit deux blocs d’information :
- les variables de l’utilisateur (appelées « extra_vars ») qui proviennent du formulaire du service (survey) ;
- une variable « squest » qui contient toutes les informations sur la requête et l’instance en attente sur Squest.
Notre playbook va donc se servir des « extra_vars » pour créer la ressource, dans notre exemple, un fichier. Nous aurons donc un formulaire qui demande un nom de fichier et un contenu.
Et enfin le playbook va se servir de la variable « squest » pour connaitre l’identifiant de l’instance en attente afin de lui donner des informations (spec) qui permettront de l’identifier de façon formelle dans un prochain appel.
Voici un exemple d’une variable « squest » que le playbook va recevoir :
squest:
request:
instance:
id: 1
name: test
service: 1
spec:
file_name: foo.conf
state: PROVISIONING
Voilà notre playbook de création au complet. (Les variables « file_name » et « file_content » proviennent du formulaire du « job template » et sont donc injectées au moment de l’exécution) :
- hosts: squest_testing
become: False
gather_facts: False
tasks:
- name: Generate UUID
set_fact:
uuid_file: "{{ file_name | to_uuid }}"
- name: Generate path
set_fact:
file_path: "/tmp/squest_functional_test/{{ uuid_file }}"
- name: Prints variables
ansible.builtin.debug:
msg:
- "UUID: {{ uuid_file }}"
- "file_name: {{ file_name }}"
- "file_content: {{ file_content }}"
- name: Create a directory with UUID
ansible.builtin.file:
path: "{{ file_path }}"
state: directory
recurse: yes
mode: u+rw,g-wx,o-wx
modification_time: preserve
access_time: preserve
- name: Write the given content in file
ansible.builtin.copy:
content: "{{ file_content }}"
dest: "{{ file_path }}/{{ file_name }}"
- name: Update squest instance with spec
uri:
validate_certs: no
url: "{{ squest_api_url }}/service_catalog/admin/instance/{{ squest['request']['instance']['id'] }}/"
headers:
Authorization: "Token {{ squest_token }}"
method: PATCH
body:
spec:
file_name: "{{ file_name }}"
uuid_file: "{{ uuid_file }}"
status_code: 200
body_format: json
Vous aurez remarqué que, dans cet exemple, nous générons notre propre identifiant unique (uuid).
L’identifiant unique va totalement dépendre du service que vous souhaitez exposer. L’idée est de nourrir le spec de l’instance avec des informations qui permettront à un autre playbook de modifier cette instance précise et pas une autre.
Si, par exemple, votre service propose la création d’une base de données dans un serveur Postgres, l’identifiant unique de cette base sera son nom et le nom du serveur qui l’héberge.
Mise à jour ou suppression d’un service
Pour chaque service dans le catalogue de Squest il est possible d’attacher des « opérations » qui permettent de gérer le cycle de vie de l’objet créé via ce service. Une opération correspond à un « job template » et donc un playbook Ansible.
Ce nouveau playbook devra lire les informations envoyées dans la variable « squest » et plus particulièrement les valeurs placées dans le champ « spec » afin de mettre à jour l’objet qui avait été créé dans l’opération de provisionnement.
Si l’on repart de notre exemple, et que nous souhaitons cette fois proposer a l’utilisateur de modifier le contenu du fichier qu’il avait créé. Au moment de l’appel, Squest va automatiquement attacher la variable « squest » avec toutes les informations « spec » fournies au moment du provisionnement de l’instance.
La séquence est cette fois-ci la suivante :
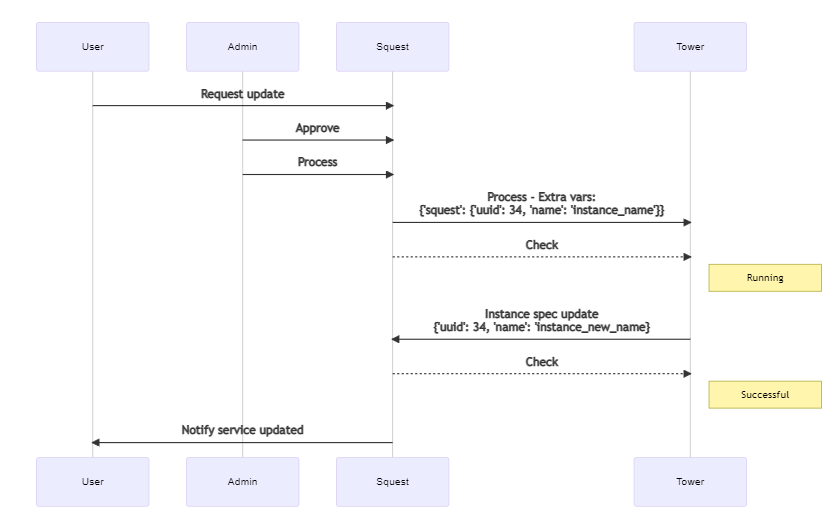
Voici un exemple de variable « squest » qu’un playbook pourrait recevoir :
squest:
request:
instance:
id: 1
state: UPDATING
spec:
file_name: 'my_file.txt'
uuid_file: 51b1d14c-cedf-5837-9063-b8cb45f950fe
Et voici un exemple de code Ansible qui permettrait la mise à jour du fichier :
- hosts: squest_testing
become: False
gather_facts: False
tasks:
- name: Get UUID and file name from Squest
set_fact:
uuid_file: "{{ squest['request']['instance']['spec']['uuid_file'] }}"
file_name: "{{ squest['request']['instance']['spec']['file_name'] }}"
- name: Generate path
set_fact:
file_path: "/tmp/squest_functional_test/{{ uuid_file }}"
- name: Prints variables
ansible.builtin.debug:
msg:
- "UUID: {{ uuid_file }}"
- "file_name: {{ file_name }}"
- "file_content: {{ file_content }}"
- name: Write the given content in file
ansible.builtin.copy:
content: "{{ file_content }}"
dest: "{{ file_path }}/{{ file_name }}"
Dans l’exemple nous avons effectué une mise à jour, mais nous aurions pu tout aussi bien supprimer le fichier et donc l’instance sur Squest.